-
 甘特圖怎么制作更方便?甘特圖制作方法" title="甘特圖怎么制作更方便?甘特圖制作方法" width="200" height="150">
甘特圖怎么制作更方便?甘特圖制作方法" title="甘特圖怎么制作更方便?甘特圖制作方法" width="200" height="150">
-
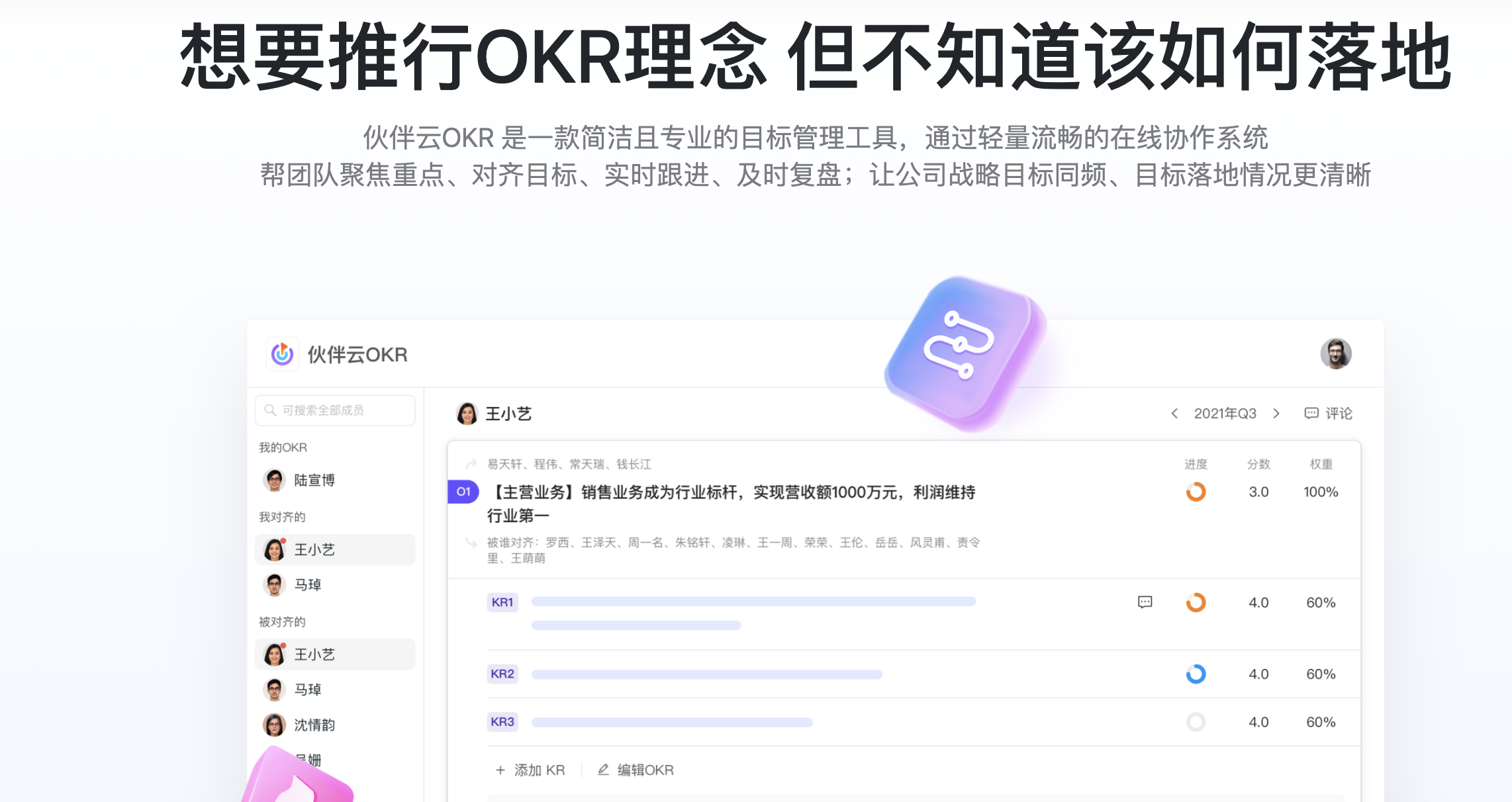 OKR的實施標準步驟是什么?成功實施落地OKR的要點" title="OKR的實施標準步驟是什么?成功實施落地OKR的要點" width="200" height="150">
OKR的實施標準步驟是什么?成功實施落地OKR的要點" title="OKR的實施標準步驟是什么?成功實施落地OKR的要點" width="200" height="150">
-

《大數據技術叢書 Flink原理、實戰與性能優化》—1.4.2 基本架構圖
所有內容 ?2022-05-301.4.2 基本架構圖 Flink系統架構設計如圖1-6所示,可以看出Flink整個系統主要由兩個組件組成,分別為JobManager和TaskManager,Flink架構也遵循Master-Sla...
-

大數據基礎學習四:偽分布式 Hadoop 在 Ubuntu 上的安裝流程完整步驟、易錯點分析及需要注意的問題
所有內容 ?2022-05-30文章目錄 前言 一、創建 Ubuntu 用戶 二、安裝 Java 2.1、查看本地 Java 版本 2.2、驗證 Java 在本地的配置情況 三、安裝 ssh 服務 3.1、安裝 openssh-se...
-

-

《Spark Streaming實時流式大數據處理實戰》 ——3.9 本 章 小 結
所有內容 ?2022-05-303.9? 本 章 小 結 * RDD是Spark內部的一種數據結構,用于記錄分布式數據。 * RDD的核心屬性有5個,其中并發量的大小由partition決定。 * RDD由數據源或者其他RDD通過T...
-

《Spark Streaming實時流式大數據處理實戰》 ——2.2.5 Spark On Mesos模式
所有內容 ?2022-05-292.2.5? Spark On Mesos模式 Mesos是Apache下的開源分布式資源管理框架,同Yarn類似,Spark也提供了利用Mesos進行資源管理的方式,即Spark On Mesos模...
-

《Spark Streaming實時流式大數據處理實戰》 ——2.2.4 Spark On Yarn模式
所有內容 ?2022-05-292.2.4? Spark On Yarn模式 Spark在0.6.0版本之后,添加了對Yarn模式的支持。通常,當我們已經部署了Hadoop集群時,可以將Spark統一在Yarn模式下進行資源分配管理...
-

《Spark Streaming實時流式大數據處理實戰》 ——3.7 共 享 變 量
所有內容 ?2022-05-293.7? 共 享 變 量 通過前面的介紹,我們知道Spark是多機器集群部署的,分為Driver、Master和Worker。Master負責資源調度,Worker是不同的運算節點,由Master統一...
-

-

-

大數據時代下,物聯網技術在車聯網上的應用
所有內容 ?2022-05-29內容摘要 首先概述了物聯網及大數據的主要概念,分析了物聯網背后大數據的價值,之后分析了車聯網在大數據時代之下與物聯網的相互關系以及 發展的模式展望。展望包括交通指揮系統、交通信息管理系統、交通危機處理...