-
 甘特圖怎么制作更方便?甘特圖制作方法" title="甘特圖怎么制作更方便?甘特圖制作方法" width="200" height="150">
甘特圖怎么制作更方便?甘特圖制作方法" title="甘特圖怎么制作更方便?甘特圖制作方法" width="200" height="150">
-
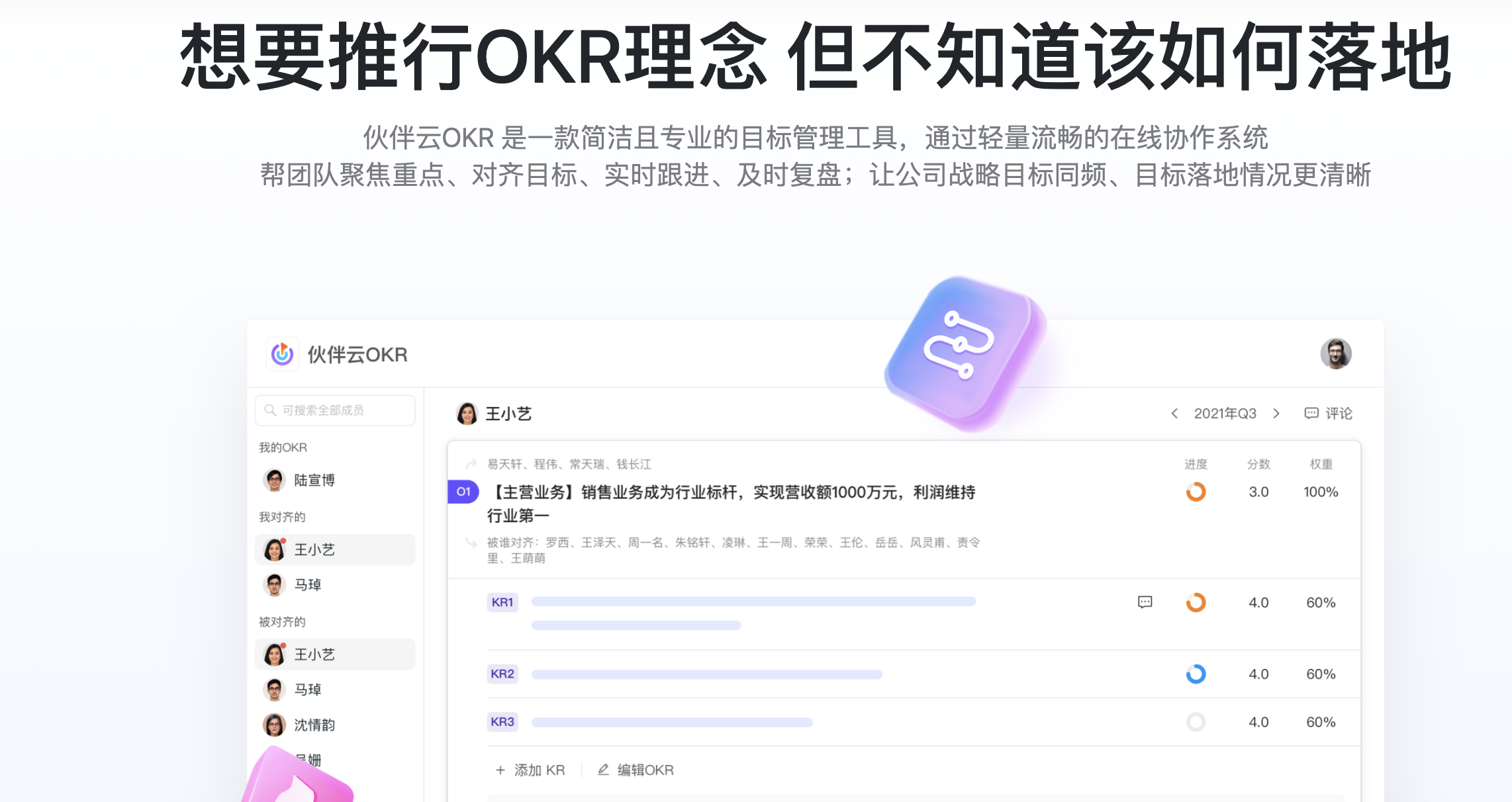 OKR的實施標準步驟是什么?成功實施落地OKR的要點" title="OKR的實施標準步驟是什么?成功實施落地OKR的要點" width="200" height="150">
OKR的實施標準步驟是什么?成功實施落地OKR的要點" title="OKR的實施標準步驟是什么?成功實施落地OKR的要點" width="200" height="150">
-

《Spark Streaming實時流式大數據處理實戰》 ——2.3 搭建開發環境
所有內容 ?2022-05-302.3? 搭建開發環境 在2.2節中對Spark的幾種運行模式做了介紹,本書在進行實戰的過程中重點以Spark Standalone模式進行,該模式也可以在生產環境中直接部署,不依賴于其他框架模式。當...
-

《Spark Streaming實時流式大數據處理實戰》
所有內容 ?2022-05-30Spark Streaming實時流式 大數據處理實戰 肖力濤? 編著 前言 為什么要寫這本書? 對于計算機從業人員和在校大學生而言,多少都會接觸到數據處理,如簡單的信息管理系統和利用關系型數據庫設計...
-

《Spark Streaming實時流式大數據處理實戰》 ——3.9 本 章 小 結
所有內容 ?2022-05-303.9? 本 章 小 結 * RDD是Spark內部的一種數據結構,用于記錄分布式數據。 * RDD的核心屬性有5個,其中并發量的大小由partition決定。 * RDD由數據源或者其他RDD通過T...
-

《Spark Streaming實時流式大數據處理實戰》 ——2.2.5 Spark On Mesos模式
所有內容 ?2022-05-292.2.5? Spark On Mesos模式 Mesos是Apache下的開源分布式資源管理框架,同Yarn類似,Spark也提供了利用Mesos進行資源管理的方式,即Spark On Mesos模...
-

《Spark Streaming實時流式大數據處理實戰》 ——2.2.4 Spark On Yarn模式
所有內容 ?2022-05-292.2.4? Spark On Yarn模式 Spark在0.6.0版本之后,添加了對Yarn模式的支持。通常,當我們已經部署了Hadoop集群時,可以將Spark統一在Yarn模式下進行資源分配管理...
-

《Spark Streaming實時流式大數據處理實戰》 ——3.7 共 享 變 量
所有內容 ?2022-05-293.7? 共 享 變 量 通過前面的介紹,我們知道Spark是多機器集群部署的,分為Driver、Master和Worker。Master負責資源調度,Worker是不同的運算節點,由Master統一...
-

《Spark Streaming實時流式大數據處理實戰》 ——1 初識Spark
所有內容 ?2022-05-29第1篇 Spark基礎 (? 第1章? 初識Spark (? 第2章? Spark運行與開發環境 (? 第3章? Spark編程模型 第1章? 初識Spark 筆者目前正在使用微軟的Word進行書籍的...
-

《Spark Streaming實時流式大數據處理實戰》 ——3.6 RDD持久化(Cachinng/Persistence
所有內容 ?2022-05-283.6? RDD持久化(Cachinng/Persistence) 前面幾節介紹了RDD的各種細節,本節將介紹Spark賦予RDD的另一個特性,即持久化(Persisting/Cache)。這個概念其...