
小白進(jìn)階之 Scrapy 第六篇 Scrapy-Redis 詳解
Scrapy-Redis 詳解
通常我們?cè)谝粋€(gè)站站點(diǎn)進(jìn)行采集的時(shí)候,如果是小站的話 我們使用 scrapy 本身就可以滿足。 但是如果在面對(duì)一些比較大型的站點(diǎn)的時(shí)候,單個(gè) scrapy 就顯得力不從心了。 要是我們能夠多個(gè) Scrapy 一起采集該多好啊 人多力量大。 很遺憾 Scrapy 官方并不支持多個(gè)同時(shí)采集一個(gè)站點(diǎn),雖然官方給出一個(gè)方法: 將一個(gè)站點(diǎn)的分割成幾部分 交給不同的 scrapy 去采集 似乎是個(gè)解決辦法,但是很麻煩誒!畢竟分割很麻煩的哇 下面就改輪到我們的額主角 Scrapy-Redis 登場(chǎng)了!
什么??你這么就登場(chǎng)了?還沒說為什么呢?
好吧 為了簡(jiǎn)單起見 就用官方圖來簡(jiǎn)單說明一下: 這張圖大家相信大家都很熟悉了。重點(diǎn)看一下 SCHEDULER 1. 先來看看官方對(duì)于 SCHEDULER 的定義: SCHEDULER 接受來自 Engine 的 Requests, 并將它們放入隊(duì)列(可以按順序優(yōu)先級(jí)),以便在之后將其提供給 Engine 點(diǎn)我看文檔 2. 現(xiàn)在我們來看看 SCHEDULER 都提供了些什么功能: 根據(jù)官方文檔說明 在我們沒有沒有指定 SCHEDULER 參數(shù)時(shí),默認(rèn)使用:’scrapy.core.scheduler.Scheduler’ 作為 SCHEDULER (調(diào)度器) scrapy.core.scheduler.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
class Scheduler(object):
def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None,
logunser=False, stats=None, pqclass=None):
self.df = dupefilter
self.dqdir = self._dqdir(jobdir)
self.pqclass = pqclass
self.dqclass = dqclass
self.mqclass = mqclass
self.logunser = logunser
self.stats = stats
# 注意在scrpy中優(yōu)先注意這個(gè)方法,此方法是一個(gè)鉤子 用于訪問當(dāng)前爬蟲的配置
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
# 獲取去重用的類 默認(rèn):scrapy.dupefilters.RFPDupeFilter
dupefilter_cls = load_object(settings['DUPEFILTER_CLASS'])
# 對(duì)去重類進(jìn)行配置from_settings 在 scrapy.dupefilters.RFPDupeFilter 43行
# 這種調(diào)用方式對(duì)于IDE跳轉(zhuǎn)不是很好 所以需要自己去找
# @classmethod
# def from_settings(cls, settings):
# debug = settings.getbool('DUPEFILTER_DEBUG')
# return cls(job_dir(settings), debug)
# 上面就是from_settings方法 其實(shí)就是設(shè)置工作目錄 和是否開啟debug
dupefilter = dupefilter_cls.from_settings(settings)
# 獲取優(yōu)先級(jí)隊(duì)列 類對(duì)象 默認(rèn):queuelib.pqueue.PriorityQueue
pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE'])
# 獲取磁盤隊(duì)列 類對(duì)象(SCHEDULER使用磁盤存儲(chǔ) 重啟不會(huì)丟失)
dqclass = load_object(settings['SCHEDULER_DISK_QUEUE'])
# 獲取內(nèi)存隊(duì)列 類對(duì)象(SCHEDULER使用內(nèi)存存儲(chǔ) 重啟會(huì)丟失)
mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE'])
# 是否開啟debug
logunser = settings.getbool('LOG_UNSERIALIZABLE_REQUESTS', settings.getbool('SCHEDULER_DEBUG'))
# 將這些參數(shù)傳遞給 __init__方法
return cls(dupefilter, jobdir=job_dir(settings), logunser=logunser,
stats=crawler.stats, pqclass=pqclass, dqclass=dqclass, mqclass=mqclass)
def has_pending_requests(self):
"""檢查是否有沒處理的請(qǐng)求"""
return len(self) > 0
def open(self, spider):
"""Engine創(chuàng)建完畢之后會(huì)調(diào)用這個(gè)方法"""
self.spider = spider
# 創(chuàng)建一個(gè)有優(yōu)先級(jí)的內(nèi)存隊(duì)列 實(shí)例化對(duì)象
# self.pqclass 默認(rèn)是:queuelib.pqueue.PriorityQueue
# self._newmq 會(huì)返回一個(gè)內(nèi)存隊(duì)列的 實(shí)例化對(duì)象 在110 111 行
self.mqs = self.pqclass(self._newmq)
# 如果self.dqdir 有設(shè)置 就創(chuàng)建一個(gè)磁盤隊(duì)列 否則self.dqs 為空
self.dqs = self._dq() if self.dqdir else None
# 獲得一個(gè)去重實(shí)例對(duì)象 open 方法是從BaseDupeFilter繼承的
# 現(xiàn)在我們可以用self.df來去重啦
return self.df.open()
def close(self, reason):
"""當(dāng)然Engine關(guān)閉時(shí)"""
# 如果有磁盤隊(duì)列 則對(duì)其進(jìn)行dump后保存到active.json文件中
if self.dqs:
prios = self.dqs.close()
with open(join(self.dqdir, 'active.json'), 'w') as f:
json.dump(prios, f)
# 然后關(guān)閉去重
return self.df.close(reason)
def enqueue_request(self, request):
"""添加一個(gè)Requests進(jìn)調(diào)度隊(duì)列"""
# self.df.request_seen是檢查這個(gè)Request是否已經(jīng)請(qǐng)求過了 如果有會(huì)返回True
if not request.dont_filter and self.df.request_seen(request):
# 如果Request的dont_filter屬性沒有設(shè)置(默認(rèn)為False)和 已經(jīng)存在則去重
# 不push進(jìn)隊(duì)列
self.df.log(request, self.spider)
return False
# 先嘗試將Request push進(jìn)磁盤隊(duì)列
dqok = self._dqpush(request)
if dqok:
# 如果成功 則在記錄一次狀態(tài)
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
# 不能添加進(jìn)磁盤隊(duì)列則會(huì)添加進(jìn)內(nèi)存隊(duì)列
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
def next_request(self):
"""從隊(duì)列中獲取一個(gè)Request"""
# 優(yōu)先從內(nèi)存隊(duì)列中獲取
request = self.mqs.pop()
if request:
self.stats.inc_value('scheduler/dequeued/memory', spider=self.spider)
else:
# 不能獲取的時(shí)候從磁盤隊(duì)列隊(duì)里獲取
request = self._dqpop()
if request:
self.stats.inc_value('scheduler/dequeued/disk', spider=self.spider)
if request:
self.stats.inc_value('scheduler/dequeued', spider=self.spider)
# 將獲取的到Request返回給Engine
return request
def __len__(self):
return len(self.dqs) + len(self.mqs) if self.dqs else len(self.mqs)
def _dqpush(self, request):
if self.dqs is None:
return
try:
reqd = request_to_dict(request, self.spider)
self.dqs.push(reqd, -request.priority)
except ValueError as e: # non serializable request
if self.logunser:
msg = ("Unable to serialize request: %(request)s - reason:"
" %(reason)s - no more unserializable requests will be"
" logged (stats being collected)")
logger.warning(msg, {'request': request, 'reason': e},
exc_info=True, extra={'spider': self.spider})
self.logunser = False
self.stats.inc_value('scheduler/unserializable',
spider=self.spider)
return
else:
return True
def _mqpush(self, request):
self.mqs.push(request, -request.priority)
def _dqpop(self):
if self.dqs:
d = self.dqs.pop()
if d:
return request_from_dict(d, self.spider)
def _newmq(self, priority):
return self.mqclass()
def _newdq(self, priority):
return self.dqclass(join(self.dqdir, 'p%s' % priority))
def _dq(self):
activef = join(self.dqdir, 'active.json')
if exists(activef):
with open(activef) as f:
prios = json.load(f)
else:
prios = ()
q = self.pqclass(self._newdq, startprios=prios)
if q:
logger.info("Resuming crawl (%(queuesize)d requests scheduled)",
{'queuesize': len(q)}, extra={'spider': self.spider})
return q
def _dqdir(self, jobdir):
if jobdir:
dqdir = join(jobdir, 'requests.queue')
if not exists(dqdir):
os.makedirs(dqdir)
return dqdir
只挑了一些重點(diǎn)的寫了一些注釋剩下大家自己領(lǐng)會(huì) (才不是我懶哦) 從上面的代碼 我們可以很清楚的知道 SCHEDULER 的主要是完成了 push Request pop Request 和 去重的操作。 而且 queue 操作是在內(nèi)存隊(duì)列中完成的。 大家看 queuelib.queue 就會(huì)發(fā)現(xiàn)基于內(nèi)存的(deque) 那么去重呢?
1
2
3
4
5
6
7
8
階之 Scrapy 第六篇 Scrapy-Redis 詳解")
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
# 此處可以看到去重其實(shí)打開了一個(gè)名叫 requests.seen的文件
# 如果是使用的磁盤的話
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
# 判斷我們的請(qǐng)求是否在這個(gè)在集合中
return True
# 沒有在集合就添加進(jìn)去
self.fingerprints.add(fp)
# 如果用的磁盤隊(duì)列就寫進(jìn)去記錄一下
if self.file:
self.file.write(fp + os.linesep)
按照正常流程就是大家都會(huì)進(jìn)行重復(fù)的采集;我們都知道進(jìn)程之間內(nèi)存中的數(shù)據(jù)不可共享的,那么你在開啟多個(gè)Scrapy的時(shí)候,它們相互之間并不知道對(duì)方采集了些什么那些沒有沒采集。那就大家伙兒自己玩自己的了。完全沒沒有效率的提升啊!  怎么解決呢? 這就是我們Scrapy-Redis解決的問題了,不能協(xié)作不就是因?yàn)镽equest 和 去重這兩個(gè) 不能共享嗎? 那我把這兩個(gè)獨(dú)立出來好了。 將Scrapy中的SCHEDULER組件獨(dú)立放到大家都能訪問的地方不就OK啦!加上scrapy-redis后流程圖就應(yīng)該變成這樣了? 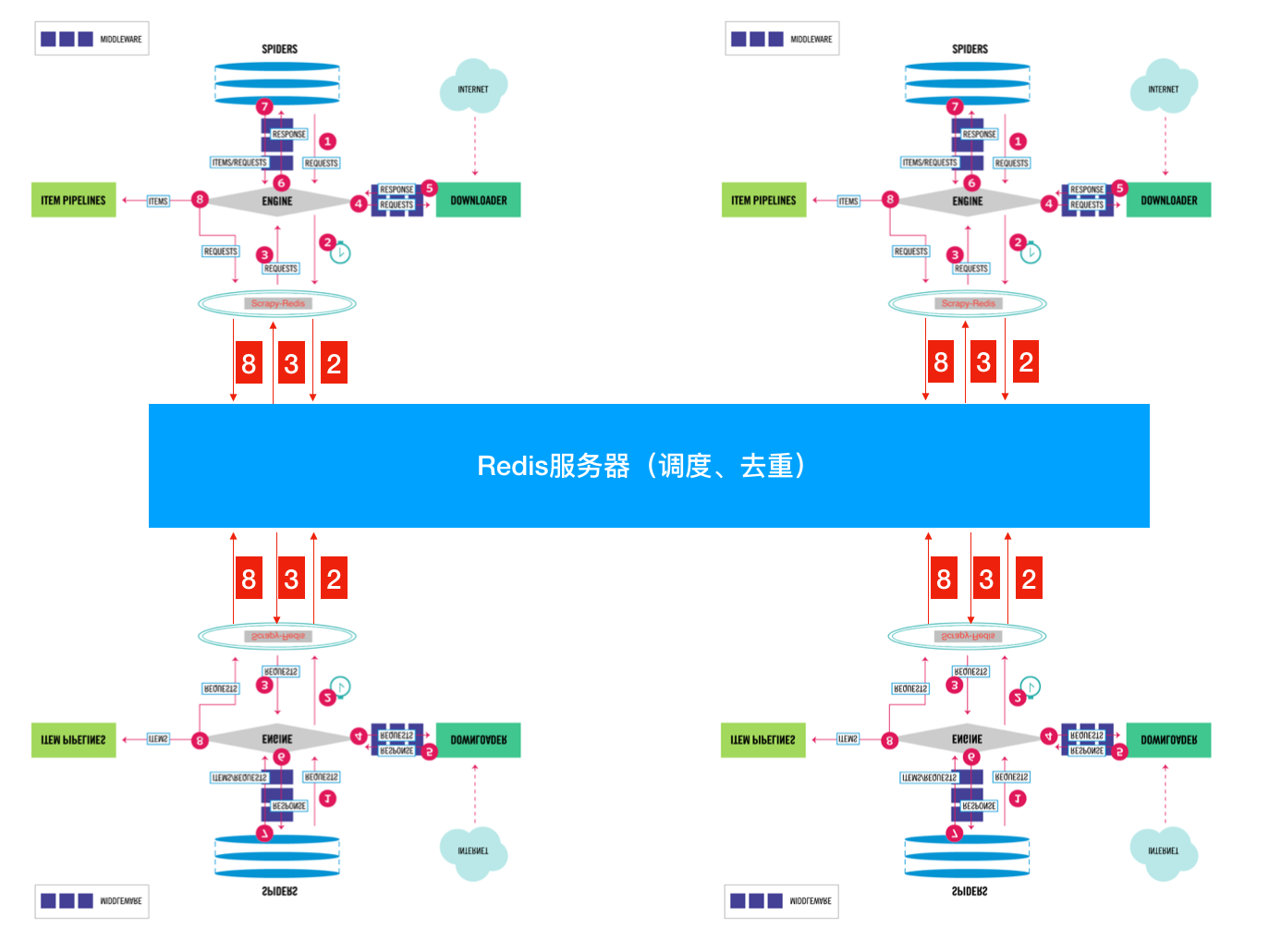 So············· 這樣是不是看起來就清楚多了??? 下面我們來看看Scrapy-Redis是怎么處理的? scrapy_redis.scheduler.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
class Scheduler(object):
"""Redis-based scheduler
Settings
--------
SCHEDULER_PERSIST : bool (default: False)
Whether to persist or clear redis queue.
SCHEDULER_FLUSH_ON_START : bool (default: False)
Whether to flush redis queue on start.
SCHEDULER_IDLE_BEFORE_CLOSE : int (default: 0)
How many seconds to wait before closing if no message is received.
SCHEDULER_QUEUE_KEY : str
Scheduler redis key.
SCHEDULER_QUEUE_CLASS : str
Scheduler queue class.
SCHEDULER_DUPEFILTER_KEY : str
Scheduler dupefilter redis key.
SCHEDULER_DUPEFILTER_CLASS : str
Scheduler dupefilter class.
SCHEDULER_SERIALIZER : str
Scheduler serializer.
"""
def __init__(self, server,
persist=False,
flush_on_start=False,
queue_key=defaults.SCHEDULER_QUEUE_KEY,
queue_cls=defaults.SCHEDULER_QUEUE_CLASS,
dupefilter_key=defaults.SCHEDULER_DUPEFILTER_KEY,
dupefilter_cls=defaults.SCHEDULER_DUPEFILTER_CLASS,
idle_before_close=0,
serializer=None):
"""Initialize scheduler.
Parameters
----------
server : Redis
這是Redis實(shí)例
persist : bool
是否在關(guān)閉時(shí)清空Requests.默認(rèn)值是False。
flush_on_start : bool
是否在啟動(dòng)時(shí)清空Requests。 默認(rèn)值是False。
queue_key : str
Request隊(duì)列的Key名字
queue_cls : str
隊(duì)列的可導(dǎo)入路徑(就是使用什么隊(duì)列)
dupefilter_key : str
去重隊(duì)列的Key
dupefilter_cls : str
去重類的可導(dǎo)入路徑。
idle_before_close : int
等待多久關(guān)閉
"""
if idle_before_close < 0:
raise TypeError("idle_before_close cannot be negative")
self.server = server
self.persist = persist
self.flush_on_start = flush_on_start
self.queue_key = queue_key
self.queue_cls = queue_cls
self.dupefilter_cls = dupefilter_cls
self.dupefilter_key = dupefilter_key
self.idle_before_close = idle_before_close
self.serializer = serializer
self.stats = None
def __len__(self):
return len(self.queue)
@classmethod
def from_settings(cls, settings):
kwargs = {
'persist': settings.getbool('SCHEDULER_PERSIST'),
'flush_on_start': settings.getbool('SCHEDULER_FLUSH_ON_START'),
'idle_before_close': settings.getint('SCHEDULER_IDLE_BEFORE_CLOSE'),
}
# If these values are missing, it means we want to use the defaults.
optional = {
# TODO: Use custom prefixes for this settings to note that are
# specific to scrapy-redis.
'queue_key': 'SCHEDULER_QUEUE_KEY',
'queue_cls': 'SCHEDULER_QUEUE_CLASS',
'dupefilter_key': 'SCHEDULER_DUPEFILTER_KEY',
# We use the default setting name to keep compatibility.
'dupefilter_cls': 'DUPEFILTER_CLASS',
'serializer': 'SCHEDULER_SERIALIZER',
}
# 從setting中獲取配置組裝成dict(具體獲取那些配置是optional字典中key)
for name, setting_name in optional.items():
val = settings.get(setting_name)
if val:
kwargs[name] = val
# Support serializer as a path to a module.
if isinstance(kwargs.get('serializer'), six.string_types):
kwargs['serializer'] = importlib.import_module(kwargs['serializer'])
# 或得一個(gè)Redis連接
server = connection.from_settings(settings)
# Ensure the connection is working.
server.ping()
return cls(server=server, **kwargs)
@classmethod
def from_crawler(cls, crawler):
instance = cls.from_settings(crawler.settings)
# FIXME: for now, stats are only supported from this constructor
instance.stats = crawler.stats
return instance
def open(self, spider):
self.spider = spider
try:
# 根據(jù)self.queue_cls這個(gè)可以導(dǎo)入的類 實(shí)例化一個(gè)隊(duì)列
self.queue = load_object(self.queue_cls)(
server=self.server,
spider=spider,
key=self.queue_key % {'spider': spider.name},
serializer=self.serializer,
)
except TypeError as e:
raise ValueError("Failed to instantiate queue class '%s': %s",
self.queue_cls, e)
try:
# 根據(jù)self.dupefilter_cls這個(gè)可以導(dǎo)入的類 實(shí)例一個(gè)去重集合
# 默認(rèn)是集合 可以實(shí)現(xiàn)自己的去重方式 比如 bool 去重
self.df = load_object(self.dupefilter_cls)(
server=self.server,
key=self.dupefilter_key % {'spider': spider.name},
debug=spider.settings.getbool('DUPEFILTER_DEBUG'),
)
except TypeError as e:
raise ValueError("Failed to instantiate dupefilter class '%s': %s",
self.dupefilter_cls, e)
if self.flush_on_start:
self.flush()
# notice if there are requests already in the queue to resume the crawl
if len(self.queue):
spider.log("Resuming crawl (%d requests scheduled)" % len(self.queue))
def close(self, reason):
if not self.persist:
self.flush()
def flush(self):
self.df.clear()
self.queue.clear()
def enqueue_request(self, request):
"""這個(gè)和Scrapy本身的一樣"""
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
# 向隊(duì)列里面添加一個(gè)Request
self.queue.push(request)
return True
def next_request(self):
"""獲取一個(gè)Request"""
block_pop_timeout = self.idle_before_close
# block_pop_timeout 是一個(gè)等待參數(shù) 隊(duì)列沒有東西會(huì)等待這個(gè)時(shí)間 超時(shí)就會(huì)關(guān)閉
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request
def has_pending_requests(self):
return len(self) > 0
來先來看看 以上就是 Scrapy-Redis 中的 SCHEDULER 模塊。下面我們來看看 queue 和本身的什么不同: scrapy_redis.queue.py 以最常用的優(yōu)先級(jí)隊(duì)列 PriorityQueue 舉例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
class PriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
"""其實(shí)就是使用Redis的有序集合 來對(duì)Request進(jìn)行排序,這樣就可以優(yōu)先級(jí)高的在有序集合的頂層 我們只需要"""
"""從上往下依次獲取Request即可"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key)
def push(self, request):
"""Push a request"""
"""添加一個(gè)Request進(jìn)隊(duì)列"""
# self._encode_request 將Request請(qǐng)求進(jìn)行序列化
data = self._encode_request(request)
"""
d = {
'url': to_unicode(request.url), # urls should be safe (safe_string_url)
'callback': cb,
'errback': eb,
'method': request.method,
'headers': dict(request.headers),
'body': request.body,
'cookies': request.cookies,
'meta': request.meta,
'_encoding': request._encoding,
'priority': request.priority,
'dont_filter': request.dont_filter,
'flags': request.flags,
'_class': request.__module__ + '.' + request.__class__.__name__
}
data就是上面這個(gè)字典的序列化
在Scrapy.utils.reqser.py 中的request_to_dict方法中處理
"""
# 在Redis有序集合中數(shù)值越小優(yōu)先級(jí)越高(就是會(huì)被放在頂層)所以這個(gè)位置是取得 相反數(shù)
score = -request.priority
# We don't use zadd method as the order of arguments change depending on
# whether the class is Redis or StrictRedis, and the option of using
# kwargs only accepts strings, not bytes.
# ZADD 是添加進(jìn)有序集合
self.server.execute_command('ZADD', self.key, score, data)
def pop(self, timeout=0):
"""
Pop a request
timeout not support in this queue class
有序集合不支持超時(shí)所以就木有使用timeout了 這個(gè)timeout就是掛羊頭賣狗肉
"""
"""從有序集合中取出一個(gè)Request"""
# use atomic range/remove using multi/exec
"""使用multi的原因是為了將獲取Request和刪除Request合并成一個(gè)操作(原子性的)在獲取到一個(gè)元素之后 刪除它,因?yàn)橛行蚣?不像list 有pop 這種方式啊"""
pipe = self.server.pipeline()
pipe.multi()
# 取出 頂層第一個(gè)
# zrange :返回有序集 key 中,指定區(qū)間內(nèi)的成員。0,0 就是第一個(gè)了
# zremrangebyrank:移除有序集 key 中,指定排名(rank)區(qū)間內(nèi)的所有成員 0,0也就是第一個(gè)了
# 更多請(qǐng)參考Redis官方文檔
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])
以上就是 SCHEDULER 在處理 Request 的時(shí)候做的操作了。 是時(shí)候來看看 SCHEDULER 是怎么處理去重的了! 只需要注意這個(gè)?方法即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def request_seen(self, request):
"""Returns True if request was already seen.
Parameters
----------
request : scrapy.http.Request
Returns
-------
bool
"""
# 通過self.request_fingerprint 會(huì)生一個(gè)sha1的指紋
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
# 添加進(jìn)一個(gè)Redis集合如果self.key這個(gè)集合中存在fp這個(gè)指紋會(huì)返回1 不存在返回0
added = self.server.sadd(self.key, fp)
return added == 0
這樣大家就都可以訪問同一個(gè)Redis 獲取同一個(gè)spider的Request 在同一個(gè)位置去重,就不用擔(dān)心重復(fù)啦 大概就像這樣:
spider1:檢查一下這個(gè) Request 是否在 Redis 去重,如果在就證明其它的 spider 采集過啦!如果不在就添加進(jìn)調(diào)度隊(duì)列,等待別 人獲取。自己繼續(xù)干活抓取網(wǎng)頁 產(chǎn)生新的 Request 了 重復(fù)之前步驟。
spider2:以相同的邏輯執(zhí)行
可能有些小伙兒會(huì)產(chǎn)生疑問了~~!spider2 拿到了別人的 Request 了 怎么能正確的執(zhí)行呢?邏輯不會(huì)錯(cuò)嗎? 這個(gè)不用擔(dān)心啦 因?yàn)檎?Request 當(dāng)中包含了,所有的邏輯,回去看看上面那個(gè)序列化的字典。 總結(jié)一下:
1. Scrapy-Reids 就是將 Scrapy 原本在內(nèi)存中處理的 調(diào)度 (就是一個(gè)隊(duì)列 Queue)、去重、這兩個(gè)操作通過 Redis 來實(shí)現(xiàn)
多個(gè) Scrapy 在采集同一個(gè)站點(diǎn)時(shí)會(huì)使用相同的 redis key(可以理解為隊(duì)列)添加 Request 獲取 Request 去重 Request,這樣所有的 spider 不會(huì)進(jìn)行重復(fù)采集。效率自然就嗖嗖的上去了。
3. Redis 是原子性的,好處不言而喻 (一個(gè) Request 要么被處理 要么沒被處理,不存在第三可能)
另外 Scrapy-Redis 本身不支持 Redis-Cluster,大量網(wǎng)站去重的話會(huì)給單機(jī)很大的壓力(就算使用 boolfilter 內(nèi)存也不夠整啊!) 改造方式很簡(jiǎn)單:
使用 rediscluster 這個(gè)包替換掉本身的 Redis 連接
Redis-Cluster 不支持事務(wù),可以使用 lua 腳本進(jìn)行代替(lua 腳本是原子性的哦)
注意使用 lua 腳本 不能寫占用時(shí)間很長(zhǎng)的操作(畢竟一大群人等著操作 Redis 你總不能讓人家等著吧)
以上!完畢 對(duì)于懶人小伙伴兒 看看這個(gè)我改好的: 集群版 Scrapy-Redis PS: 支持 Python3.6+ 哦 ! 其余的版本沒測(cè)試過
Redis Scrapy
版權(quán)聲明:本文內(nèi)容由網(wǎng)絡(luò)用戶投稿,版權(quán)歸原作者所有,本站不擁有其著作權(quán),亦不承擔(dān)相應(yīng)法律責(zé)任。如果您發(fā)現(xiàn)本站中有涉嫌抄襲或描述失實(shí)的內(nèi)容,請(qǐng)聯(lián)系我們jiasou666@gmail.com 處理,核實(shí)后本網(wǎng)站將在24小時(shí)內(nèi)刪除侵權(quán)內(nèi)容。
版權(quán)聲明:本文內(nèi)容由網(wǎng)絡(luò)用戶投稿,版權(quán)歸原作者所有,本站不擁有其著作權(quán),亦不承擔(dān)相應(yīng)法律責(zé)任。如果您發(fā)現(xiàn)本站中有涉嫌抄襲或描述失實(shí)的內(nèi)容,請(qǐng)聯(lián)系我們jiasou666@gmail.com 處理,核實(shí)后本網(wǎng)站將在24小時(shí)內(nèi)刪除侵權(quán)內(nèi)容。
相關(guān)文章
