-
 甘特圖怎么制作更方便?甘特圖制作方法" title="甘特圖怎么制作更方便?甘特圖制作方法" width="200" height="150">
甘特圖怎么制作更方便?甘特圖制作方法" title="甘特圖怎么制作更方便?甘特圖制作方法" width="200" height="150">
-
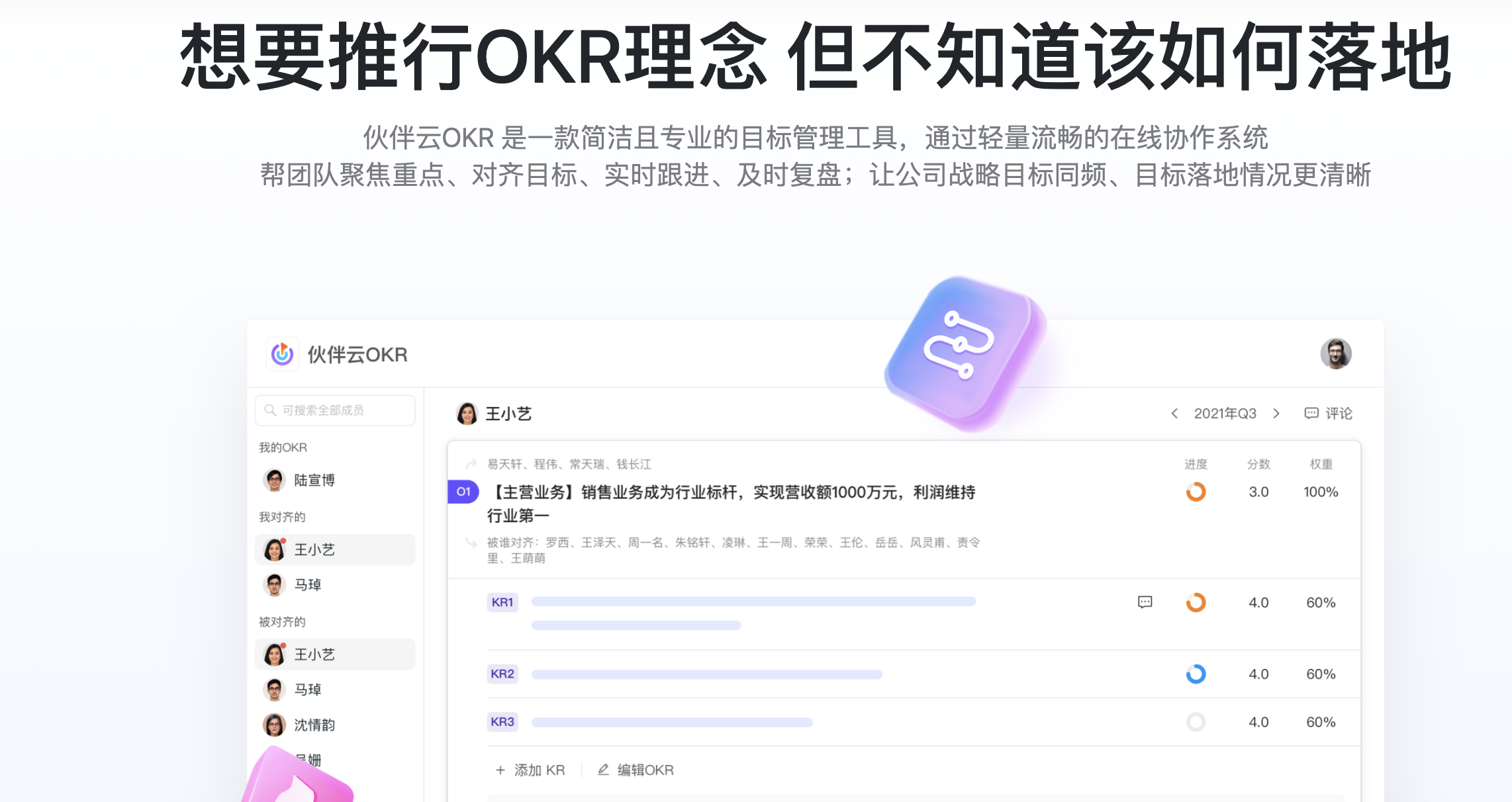 OKR的實(shí)施標(biāo)準(zhǔn)步驟是什么?成功實(shí)施落地OKR的要點(diǎn)" title="OKR的實(shí)施標(biāo)準(zhǔn)步驟是什么?成功實(shí)施落地OKR的要點(diǎn)" width="200" height="150">
OKR的實(shí)施標(biāo)準(zhǔn)步驟是什么?成功實(shí)施落地OKR的要點(diǎn)" title="OKR的實(shí)施標(biāo)準(zhǔn)步驟是什么?成功實(shí)施落地OKR的要點(diǎn)" width="200" height="150">
-
 dAPI 的安裝" title="ScrapydAPI 的安裝" width="200" height="150">
dAPI 的安裝" title="ScrapydAPI 的安裝" width="200" height="150">
-
Scrapy-Splash 的安裝
所有內(nèi)容 ?2025-04-06Scrapy-Splash 是一個(gè) Scrapy 中支持 JavaScript 渲染的工具,本節(jié)來介紹一下它的安裝方式。 Scrapy-Splash 的安裝分為兩部分,一個(gè)是是 Splash 服務(wù)的安...
-
 Redis 的安裝" title="Scrapy-Redis 的安裝" width="200" height="150">
Redis 的安裝" title="Scrapy-Redis 的安裝" width="200" height="150">
-
 框架的使用" title="Scrapy框架的使用" width="200" height="150">
框架的使用" title="Scrapy框架的使用" width="200" height="150">
-
安裝" title="Scrapy 的安裝" width="200" height="150">
-
還在焦頭爛額裸寫Scrapy?這個(gè)神器讓你90秒內(nèi)配好一個(gè)爬蟲" title="還在焦頭爛額裸寫Scrapy?這個(gè)神器讓你90秒內(nèi)配好一個(gè)爬蟲" width="200" height="150">
-
Python 爬蟲 | Scrapy 基礎(chǔ)入門篇" title="Python 爬蟲 | Scrapy 基礎(chǔ)入門篇" width="200" height="150">
-
 Python干貨:用Scrapy爬電商網(wǎng)站" title="Python干貨:用Scrapy爬電商網(wǎng)站" width="200" height="150">
Python干貨:用Scrapy爬電商網(wǎng)站" title="Python干貨:用Scrapy爬電商網(wǎng)站" width="200" height="150">
-
 | 一文帶你快速了解Scrapy框架(版本2.3.0)")
-
為空/降速/緩存")
scrapy間歇性響應(yīng)為空/降速/緩存
所有內(nèi)容 ?2022-05-29使用 scrapy訪問豆瓣的搜索接口時(shí),莫名會(huì)出現(xiàn)response json數(shù)據(jù)為空的情況。 加上回調(diào)重新請(qǐng)求 (要設(shè)置dont_filter=True 防止被過濾), 還是會(huì)出現(xiàn)異常。 最后發(fā)現(xiàn)是請(qǐng)...